Blog/Article // use case Public discussion
Description
Although not oficially specified, this format follows some strict conventions which are de facto standard. These conventions are derived from newspapers ones. A blog/article has a strong semantic structure that divides the text into logical fragments and is frequently denoted by headings. The textual content is usually accompanied with multimedia content, especially images.
Functionality
Features
Usability Features
Notes
- It is almost impossible to predict every possible type of a blog/article, therefore there is no strict set of elements that will be included in the content.
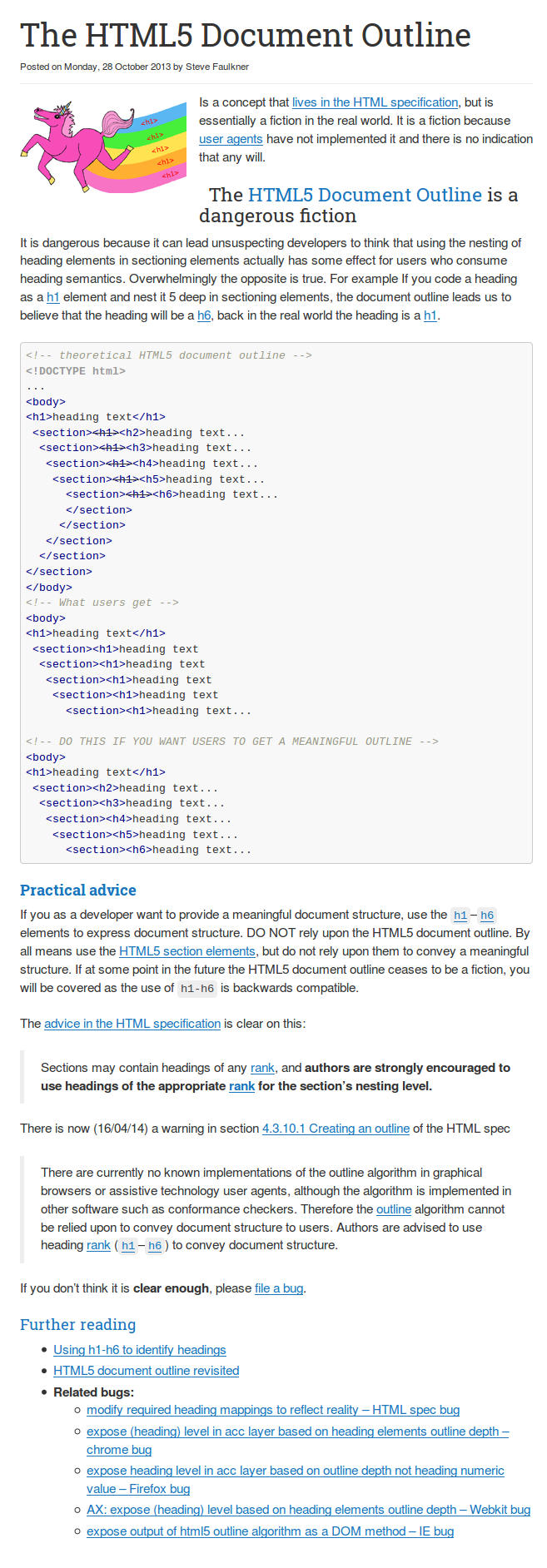
- A blog/article is not an independent form of content, but it is a part (usually the main one) of an entire webpage. As a result, it should not interfere with the webpage semantics. A blog/article is dependent on its context of appearance and its own semantic structure must be treated as a part of the semantic structure of the whole webpage. The main concern is the rank of headers to create the proper webpage outline[1] [2].
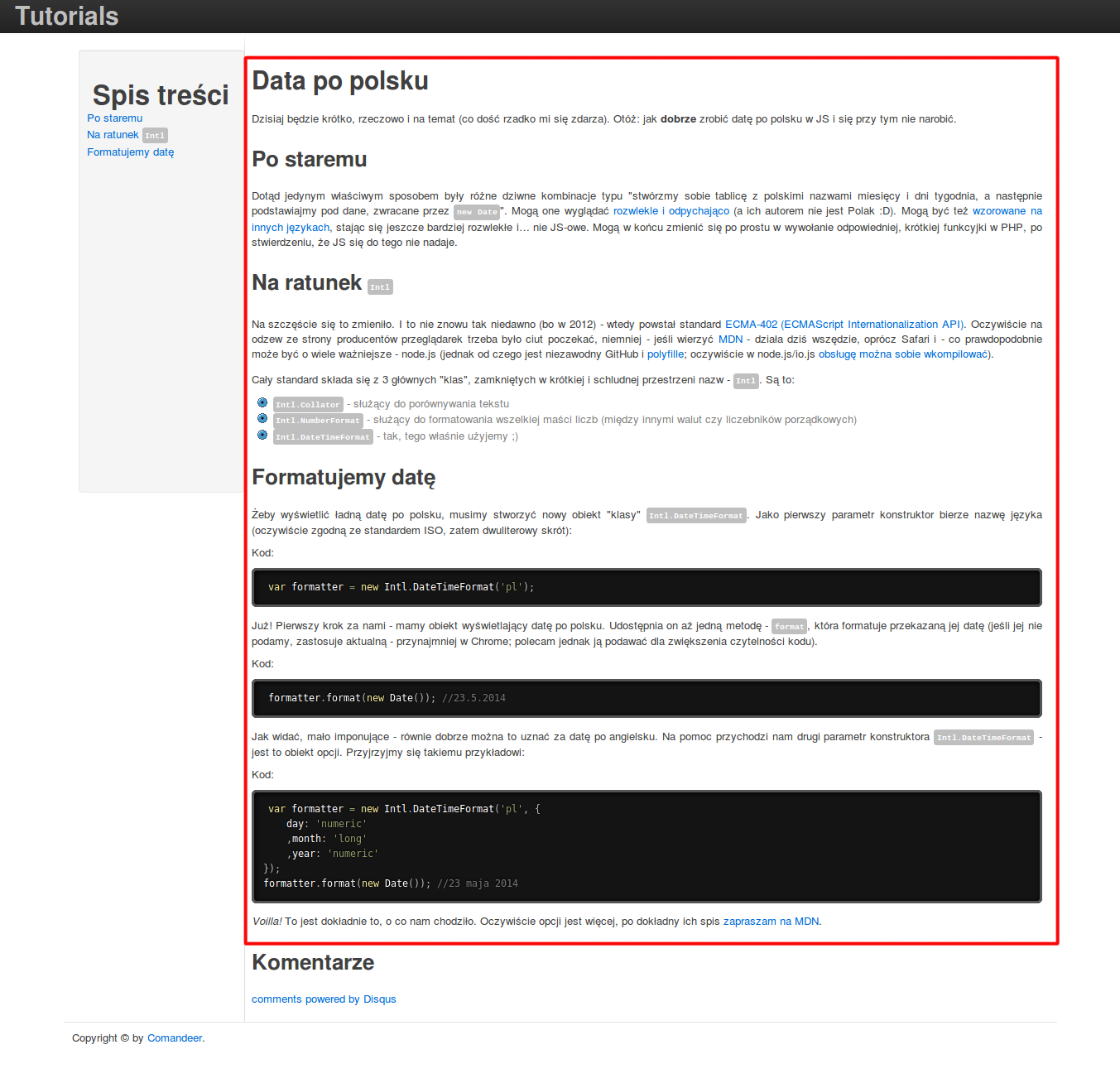
- Blogs/articles are usually written by people that do not know the semantics of HTML (as they are content creators, not web developers), therefore they tend to completely rely on the WYSIWYG approach. Content creators often treat WYSIWYM and WYSIWYG approaches as the same. As a result many blogs/articles have semantic and/or accessibility problems and could be misunderstood by people with disabilities who use Assistive Technology or by search engines, like Google or Bing. There is thus a need for a simple tool that will check the markup and report all semantic and accessibility errors[3].